2007-07-15
ボトルネックとホットスポット

昨日の RTR 読書会はパイプライン最適化の話だった. 改めて読むと面白い. 各種高速化チップスはさておき, パイプラインの遅い部分, ボトルネックを特定する方法が興味深かった. (ゲーム屋さんには当たり前の話だと思います.)
グラフィクス・アプリケーションのパイプラインはおおよそ以下のようなものだ: CPU でデータを作り, それを GPU に送る. GPU ではまず geometry ステージ (vertex shader とか) が頂点情報を計算し, それを rasterize ステージ (pixel shader とか) がピクセルに変換, frame buffer に書き込む. データは図の左から右に流れる. この流れっぷりがパイプラインと呼ばれる所以.

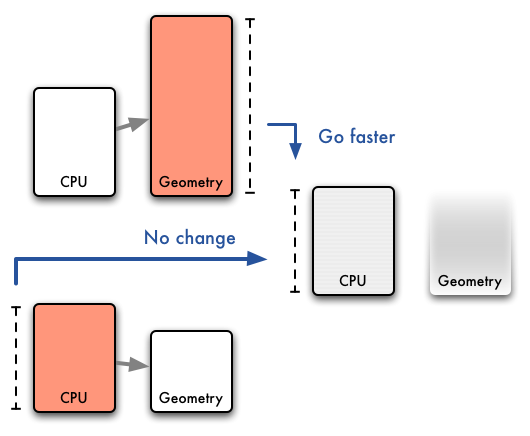
パイプラインの各ステージは基本的に並列して動く. だから全体の実行時間は最も遅いステージの所要時間になる. 各ステージの合計ではない. だから速いステージを更に速くしたところで意味がない. まさにボトルネック. ボトルネックという呼び名は素朴な世界の高速化でも使う. コンポーネントの合計処理時間が実行時間になるようなケースね. そういうのはホットスポットと呼んでおこう. 語弊が少い.
ホットスポットの世界では, ホットスポット以外を速くしても多少は意味がある. 50% の処理時間を占める部分が速くできないとき, 30% を占める部分が倍速くなれば 15% 高速になる. ボトルネックの世界では合計に意味がない. 逆に暇なステージは足並みが揃うまで負荷を増やすことができる. geometry ステージがボトルネックなら pixel shader を派手にしてもいい.

ボトルネックの世界では, CPU プロファイラの上位リストを潰していく伝統的な高速化だけだと歯が立たない. 以前 "CPU レベルで頑張る人が多いんだけど, 全然意味ないんだよねえ..." とゲーム屋さんがぼやくのを聞いた. でも頑張る人の気持ちもわかる. 世界は素朴だと信じたいんだよね. 勝手に共感.
RTR ではボトルネックを特定する方法が紹介されている. CPU ステージを調べるのは比較的簡単だ. グラフィクス API の呼び出しをダミーに差し替えればいい. ダミーを使っても速度が変わらなかったら CPU がボトルネックだとわかる. ただし, ステージそのものではなくステージ間の通信(CPU と GPU の通信)が ボトルネックになることもある. その判断には素朴な API 差し替え以上の工夫が必要になる.
GPU の各ステージを調べるのはもう少し難しい. GPU を測りたいからといって CPU ステージを無効にはできない. 入力がなくなってしまう. geometry ステージは特に難しい. 先の問題に加え, 単純に geometry 処理を無効化すると rasterize ステージの計算量まで変わってしまう. 出口にも入口にも気を使わなければいけない. だから出力を変化させず負荷を調査したい. RTR では照明の数を調節する方法が紹介されている. 照光計算を無効にして速くなれば, geometry ステージがボトルネックだとわかる. 少し一般的に言うなら, 頂点演算のうち頂点色の計算負荷を調整すればいいと言える. 頂点位置やテクスチャ座標を変えると rasterize の負荷に影響してしまう.
その rasterize ステージは簡単. 今ならシェーダを空(kill)にすればいい. frame buffer を小さくしてもいい.
...なんてのを感心しながら読んでいたら, ボトルネック解消に関する NVIDIA のスライドを教えてもらった: "Practical Performance Analysis and Tuning (2004)" RTR の議論より細かい話で, たとえばステージも 7 つに分割している. そのほか生々しすぎて門外漢には辛い話も多いけれど, 細かな落とし穴のフォローは実務で役立つのだろう.
ボトルネックとテスト可能性
先のスライドではボトルネック特定の技法を二種類に分類している.
- あるステージを書き換えてみる
- あるステージ以外を無効化してみる
あとは複数のテストをしろと補足している. 他に影響を与えずステージを変更するのは難しい. 勘違いを避けるために追試するわけね.
ボトルネックを特定するこの方法論はグラフィクス以外でも役に立つ気がする. 少しでも非同期な性質を持つプログラム, 出口と入口で時間を測るだけだと不十分なコードには こうしたアプローチが効くだろう. 友人とそんな話をした.
たとえばノンブロック I/O を使ったネットワークプログラムはこれにあたる. カーネルとアプリケーションは並列に動く. ユーザランドの処理を速くしたところで帯域がボトルネックかもしれない. 逆に自分のコードが遅いこともあるだろう. それを確かめたいなら 各ステージを差し替えられるようにしておく必要がある. システムコールをダミーに差し替えても良いだろう. (けど, もうちょっと上で切りたい...)
XHR を使ったウェブアプリケーションも非同期だ. データの送受信とクライアントコードは並列に動く. 受け取った XML を処理するコードが遅いかもしれないし, サーバや経路が遅いかもしれない. XHR の受信部分をダミーに差し替えればそれを調べることができるだろう. 非同期とは違うけれど, スクリプトの実行後に動くレイアウト処理も出口調査ができない点で 非同期と似ている. その負荷の程度もレイアウトを無効化すれば特定できる. (スタイルで工夫するといいらしい. 友人談.)
ボトルネックの特定しやすさと テスト可能性には関係がありそうだ. あるモジュールがテスト可能であるためには その依存先をテスト用スタブに差し替えられなければいけない. これは "あるステージ以外を無効化する" という条件の一般化だと言える.
ただしこの条件は十分でない. ボトルネックを調べたいならモジュール単体でなく (一部を無効化した)アプリケーション全体を動かしたいと思うだろう. アプリケーションにはそうした設定を許す柔軟さが求められる. ダミーのモジュールを作るのも面倒が多い. 正しい値を返すだけでなく, 実運用に近い負荷を作りたい. 単体テストのモックを書くよりは大変そう.
こう考えると非同期アプリケーションの高速化はとても難しいものに思えてくる. アドホックなチューニングでは歯が立ちそうにない. おそらく設計段階から計測の枠組みを仕込んでおかないとつらい. 単体テストはそう仕向ける圧力になるが, もう一歩踏み込む必要がある. こりゃ大変だわ. 世間の非同期なウェブアプリケーションが緩慢なのも仕方ない. やや同情した. ゲーム屋さんはエライ.
私も他人事みたいな顔をしてられない気がするけどね...
思いだしたようにまとめ:
- グラフィクスのパイプライン最適化は非同期アプリの高速化に応用できそう
- あるステージを書き換えてみる
- あるステージ以外を無効化してみる
- でも大変
- モジュールの依存先を差し替え可能にする必要あり
- 差し替えた状態のアプリで測定できる必要あり